
افزونگی در سرور: راهنمای جامع برای زیرساختهای بدون توقف
در دنیایی که حتی چند ثانیه قطعی سرویس میتواند میلیونها دلار ضرر به بار آورد، سرورها دیگر نمیتوانند به شانس یا کیفیت یک قطعه خاص متکی باشند. یک منبع تغذیه ممکن است بسوزد، یک فن ممکن است از کار بیفتد، یک ماژول حافظه ممکن است دچار خطا شود یا یک هارد دیسک ممکن است به پایان عمر خود برسد. در چنین شرایطی، اگر سرور فقط یک عدد از هر کدام از این اجزا داشته باشد، با خرابی هر یک، کل سیستم از کار میافتد. اینجاست که مفهوم افزونگی (Redundancy) وارد عمل میشود: هنر و علم طراحی سیستمها به گونهای که هیچ نقطه تکی وجود نداشته باشد که خرابی آن بتواند کل سرویس را متوقف کند. در این مقاله، لایههای مختلف افزونگی در سرورها، از منبع تغذیه گرفته تا شبکه و پردازنده را بررسی میکنیم.
افزونگی چیست و چرا اهمیت دارد؟
افزونگی در سرور به معنای تکثیر اجزای حیاتی سیستم است، به طوری که اگر یک جزء دچار خرابی شود، یک جزء دیگر بلافاصله و بدون وقفه جای آن را بگیرد. هدف اصلی افزونگی، افزایش قابلیت اطمینان (Reliability) و دسترسپذیری (Availability) سرویسهاست—نه لزوماً بهبود کارایی. برای مثال، در یک دیتاسنتر مالی که هر ثانیه توقف آن میتواند میلیونها دلار ضرر به بار آورد، افزونگی یک الزام استراتژیک است، نه یک انتخاب لوکس. افزونگی از طریق حذف نقاط تکخرابی (Single Point of Failure یا SPOF) محقق میشود—یعنی هر قطعهای که خرابی آن میتواند کل سرور را از کار بیندازد، باید یک نسخه پشتیبان آمادهبهکار داشته باشد.
مفهوم افزونگی را باید از دو مفهوم مشابه اما متفاوت دیگر جدا کرد: High Availability (HA) و Fault Tolerance (FT). در High Availability، هدف کاهش زمان توقف به حداقل ممکن است—سرور در صورت خرابی، برای مدت کوتاهی (چند ثانیه تا چند دقیقه) از دسترس خارج میشود و سپس با جایگزینی خودکار قطعه معیوب، به کار ادامه میدهد. اما در Fault Tolerance، هدف حذف کامل توقف است—سیستم باید بدون حتی یک میلیثانیه قطعی به کار ادامه دهد. Fault Tolerance بسیار گرانتر و پیچیدهتر است و معمولاً در سیستمهای بسیار حیاتی مانند کنترل ترافیک هوایی یا تجهیزات پزشکی به کار میرود. همچنین، افزونگی هرگز نباید با بکاپ (Backup) اشتباه گرفته شود—افزونگی برای حفظ تداوم سرویس در لحظه است، در حالی که بکاپ برای بازیابی دادهها پس از وقوع یک فاجعه (مانند حذف تصادفی دادهها، حمله باجافزاری یا آتشسوزی) طراحی شده است.
افزونگی در منبع تغذیه
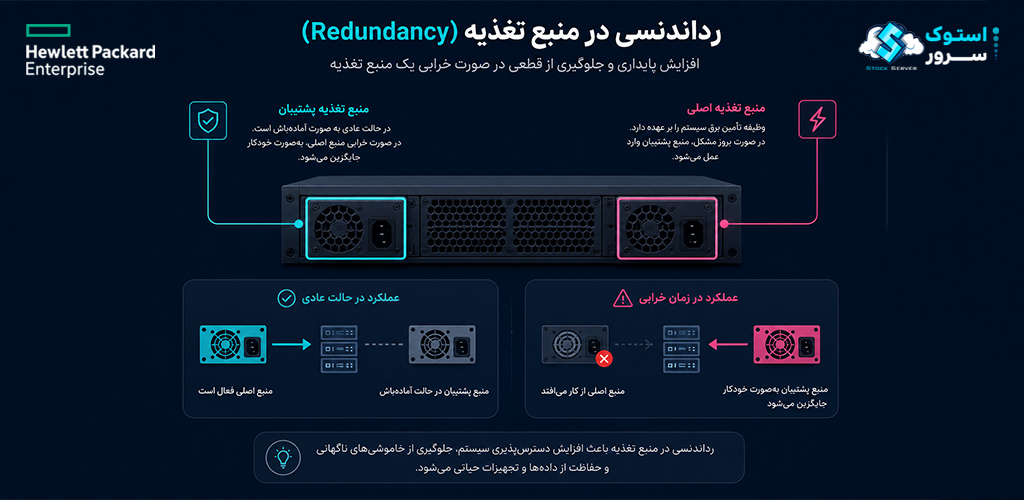
منبع تغذیه (Power Supply) یکی از حیاتیترین اجزای سرور است—بدون برق، هیچ چیز کار نمیکند. به همین دلیل، افزونگی در این بخش یکی از اولین و رایجترین انواع افزونگی است که در سرورهای سازمانی پیادهسازی میشود. سرورهایی مانند HPE ProLiant DL380 Gen9 و DL360 Gen10 معمولاً با دو یا چند منبع تغذیه Hot-Plug عرضه میشوند که در حالت عادی، بار را بین خود تقسیم میکنند. اگر یکی از منابع تغذیه خراب شود، دیگری به تنهایی کل بار را به دوش میکشد—بدون هیچ وقفهای در سرویس.
منابع تغذیه افزونه را میتوان در چندین پیکربندی مختلف تنظیم کرد. در حالت ۱+۱ (که رایجترین است)، دو منبع تغذیه وجود دارد که هرکدام به تنهایی قادر به تأمین برق کل سرور هستند. در این حالت، اگر یکی خراب شود، دیگری بدون هیچ مشکلی جای آن را میگیرد. در سناریوهای پیشرفتهتر، میتوان از N+1 یا حتی ۲N استفاده کرد. برای مثال، اگر یک سرور به ۴ منبع تغذیه نیاز داشته باشد، پیکربندی N+1 یعنی ۵ منبع تغذیه نصب شود—۴ عدد برای تأمین بار عادی و یک عدد به عنوان آمادهبهکار. پیکربندی ۲N نیز یعنی هر منبع تغذیه یک نسخه پشتیبان کامل دارد—که هزینه را دو برابر میکند اما بالاترین سطح اطمینان را ارائه میدهد.
منابع تغذیه Hot-Plug به این معنا هستند که میتوان آنها را بدون خاموش کردن سرور تعویض کرد. این قابلیت برای دیتاسنترهایی که نیاز به دسترسپذیری ۲۴/۷ دارند، حیاتی است. همچنین، منابع تغذیه مدرن با راندمان ۹۴٪ (Platinum) یا ۹۶٪ (Titanium) عرضه میشوند که علاوه بر افزونگی، مصرف برق را نیز بهینه میکنند.
افزونگی در سیستم خنککننده
پس از منبع تغذیه، سیستم خنککننده دومین بخش حیاتی است که خرابی آن میتواند به سرعت منجر به overheating و خاموشی اضطراری سرور شود. در سرورهای رکمونت مانند HPE ProLiant DL380 G9، معمولاً ۶ فن Hot-Plug در محفظه میانی نصب میشوند که به صورت N+1 پیکربندی شدهاند. این یعنی اگر یک فن از کار بیفتد، ۵ فن باقیمانده به طور خودکار سرعت خود را افزایش میدهند تا جریان هوای کافی برای خنکسازی قطعات حفظ شود، و سیستم iLO یک هشدار برای تعویض فن معیوب صادر میکند.
فنهای Hot-Plug نیز مانند منابع تغذیه، بدون نیاز به خاموش کردن سرور قابل تعویض هستند. نکته مهم دیگر، طراحی Passive بسیاری از قطعات خنککننده است—مانند هیتسینکهای پردازنده که هیچ قطعه متحرکی ندارند و صرفاً با تکیه بر جریان هوای فنها کار میکنند. این طراحی، خود نوعی افزونگی غیرمستقیم ایجاد میکند: اگر یک هیتسینک خراب شود (که تقریباً غیرممکن است چون قطعه متحرکی ندارد)، فنها میتوانند با افزایش سرعت، تا حدی کمبود خنکسازی را جبران کنند. در سرورهای پرمصرفتر که از خنککننده مایع استفاده میکنند، پمپها و مدارهای خنککننده نیز معمولاً به صورت افزونه طراحی میشوند تا خرابی یک پمپ، کل سیستم را از کار نیندازد.

افزونگی در ذخیرهسازی
وقتی صحبت از افزونگی در ذخیرهسازی میشود، RAID (Redundant Array of Independent Disks) اولین و مهمترین فناوری است که به ذهن میرسد. RAID با ترکیب چند هارد دیسک یا SSD فیزیکی در یک آرایه، افزونگی را در سطح دیسک فراهم میکند. رایجترین سطوح RAID برای افزونگی عبارتند از RAID 1 که با Mirroring کامل، هر داده را روی دو دیسک کپی میکند و اگر یک دیسک بسوزد، دیسک دوم بدون وقفه به کار ادامه میدهد. RAID 5 با توزیع Parity بین دیسکها، تحمل خرابی یک دیسک را فراهم میکند بدون آنکه نصف ظرفیت هدر برود. RAID 6 مشابه RAID 5 است اما با Parity دوگانه، تا دو دیسک میتوانند همزمان خراب شوند بدون از دست رفتن داده. RAID 10 نیز ترکیبی از Mirroring و Striping است که هم سرعت بالا دارد و هم امنیت—نیاز به حداقل ۴ دیسک دارد و نصف ظرفیت کل قابل استفاده است.
فراتر از RAID، کنترلرهای RAID خود میتوانند افزونه باشند—برخی سرورها از دو کنترلر RAID پشتیبانی میکنند که در صورت خرابی یکی، دیگری مسئولیت را بر عهده میگیرد. همچنین فناوری Hot Spare به این معناست که یک یا چند دیسک اضافی در آرایه وجود دارند که در حالت آمادهباش قرار میگیرند و به محض خرابی یک دیسک اصلی، فرآیند بازسازی (Rebuild) بهطور خودکار روی آنها آغاز میشود. کنترلرهای RAID همچنین عملیات پیشگیرانهای مانند Patrol Read را انجام میدهند که بهطور دورهای تمام بلوکهای داده را میخوانند و سلامت آنها را بررسی میکنند تا از خرابیهای خاموش جلوگیری شود. در سطح بالاتر، فناوریهایی مانند Multipath I/O امکان اتصال سرور به SAN از طریق چندین مسیر فیزیکی را فراهم میکنند—اگر یک کابل، سوئیچ یا HBA خراب شود، ترافیک از مسیر دیگر ادامه مییابد.
افزونگی در ذخیرهسازی
در سرورهای HPE از کنترلر RAID استفاده میشود که بنا به نیاز مشتری، دارای انواع مختلف میباشد
مشاهده مشخصات و قیمت کنترلرهای RAIDافزونگی در حافظه و پردازنده
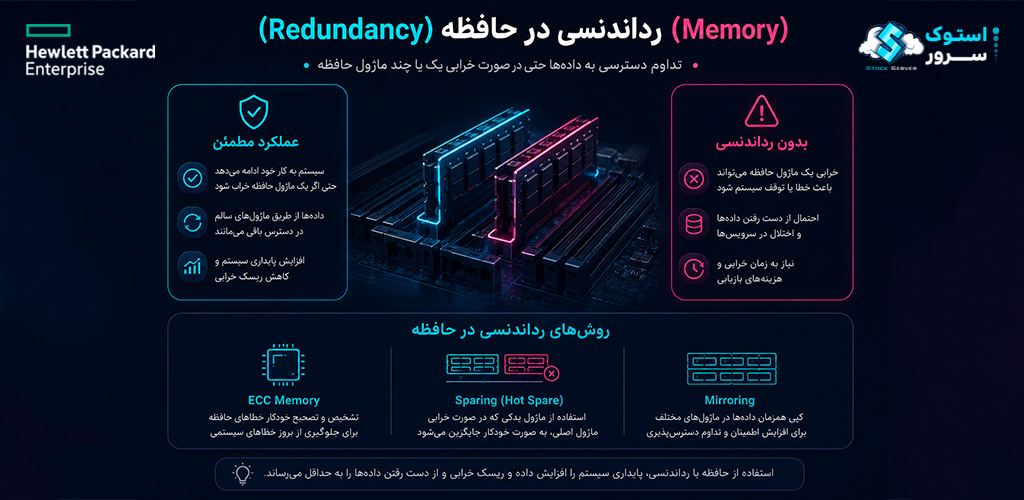
حافظه RAM یکی از حساسترین نقاط سرور است—برخلاف هارد دیسک که دادهها را به صورت پایدار ذخیره میکند، RAM فرّار است و هر خطایی در آن میتواند منجر به خرابی دادهها، کرش برنامهها یا حتی از کار افتادن کل سیستم شود. سرورهای سازمانی برای مقابله با این تهدید، از فناوریهای متعددی استفاده میکنند. Advanced ECC (Error Correction Code) میتواند خطاهای تک بیتی را تصحیح و خطاهای چند بیتی را تشخیص دهد. Memory Mirroring کل محتوای حافظه را روی دو کانال مجزا کپی میکند—اگر یک ماژول DIMM خراب شود، دادهها از روی کپی آن خوانده میشوند. Memory Rank Sparing نیز رتبههای حافظه را به عنوان آمادهبهکار نگه میدارد و در صورت افزایش خطاها در یک رتبه، بهطور خودکار آن را با رتبه یدکی جایگزین میکند.
در سطح پردازنده، افزونگی به شکل سنتی (داشتن دو پردازنده که یکی یدک دیگری باشد) تقریباً وجود ندارد—چون هزینه آن بسیار بالاست و پیچیدگیهای فنی زیادی دارد. اما سرورهای چندپردازندهای (مانند DL560 Gen10 با ۴ سوکت) به گونهای طراحی شدهاند که اگر یکی از پردازندهها خراب شود، پردازندههای باقیمانده بتوانند بار را تحمل کنند—هرچند با افت کارایی. همچنین فناوریهایی مانند CPU Hot Add در برخی سرورها امکان اضافه کردن پردازنده بدون خاموش کردن سیستم را فراهم میکنند. در عمل، افزونگی پردازنده بیشتر از طریق کلاسترینگ (Clustering) در سطح سرورها پیادهسازی میشود: اگر یک سرور کامل خراب شود، سرورهای دیگر در کلاستر، بار آن را به دوش میکشند.
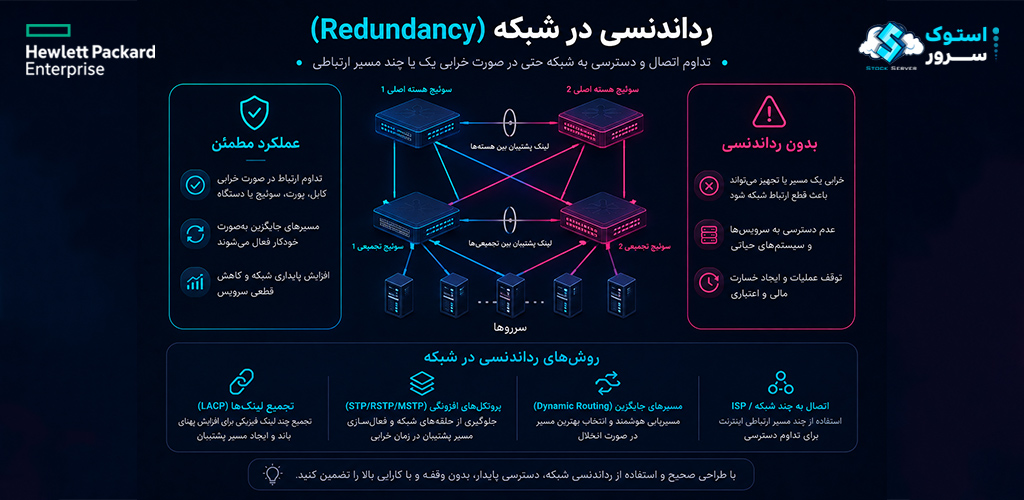
افزونگی در شبکه
شبکه، شاهرگ ارتباطی سرور با دنیای خارج است و قطعی آن میتواند سرویس را از دسترس کاربران خارج کند—حتی اگر خود سرور کاملاً سالم باشد. برای جلوگیری از این مشکل، از فناوریهای متعددی استفاده میشود. NIC Teaming (یا Bonding) چندین کارت شبکه فیزیکی را در قالب یک کارت شبکه مجازی ترکیب میکند—اگر یک پورت، کابل یا حتی یک کارت شبکه کامل خراب شود، ترافیک از طریق پورتهای باقیمانده ادامه مییابد. استاندارد IEEE 802.3ad (Link Aggregation) این فرآیند را استانداردسازی کرده و امکان ترکیب پورتها را با سوئیچهای سازگار فراهم میکند.
در سطح سوئیچ، فناوریهایی مانند HPE Intelligent Resilient Framework (IRF) چندین سوئیچ فیزیکی را به یک سوئیچ مجازی تبدیل میکنند که از دید شبکه مانند یک دستگاه واحد عمل میکند. اگر یکی از سوئیچها خراب شود، دیگری بدون وقفه به کار ادامه میدهد. همچنین Multipath I/O در شبکههای SAN، امکان اتصال سرور به ذخیرهساز از طریق چندین مسیر فیزیکی را فراهم میکند—اگر یک HBA، کابل فیبر نوری یا پورت سوئیچ خراب شود، ترافیک از مسیر جایگزین عبور میکند. در سطح نرمافزاری، فناوریهایی مانند VMware vSphere High Availability و Failover Clustering در Windows Server نیز به صورت خودکار ماشینهای مجازی را در صورت خرابی یک سرور فیزیکی، روی سرور سالم دیگر راهاندازی مجدد میکنند.
جمعبندی: یک سپر دفاعی چندلایه
افزونگی یک راهحل تکبعدی نیست—بلکه یک فلسفه طراحی است که باید در تمام لایههای زیرساخت پیادهسازی شود. از منبع تغذیه و خنککننده گرفته تا ذخیرهسازی، حافظه و شبکه، هر لایه باید به گونهای طراحی شود که خرابی یک جزء، کل سیستم را از کار نیندازد. نکته کلیدی که باید به خاطر داشت این است که افزونگی هرگز جایگزین بکاپ نیست—هیچ سطحی از RAID یا منبع تغذیه افزونه نمیتواند از دادههای شما در برابر حذف تصادفی، حمله باجافزاری یا آتشسوزی محافظت کند. یک استراتژی جامع حفاظت از داده باید هم شامل افزونگی برای تداوم سرویس باشد و هم شامل بکاپ منظم برای بازیابی در شرایط بحرانی. در نهایت، افزونگی یک سرمایهگذاری است—هزینه اولیه آن ممکن است بالا به نظر برسد، اما در مقایسه با هزینههای یک توقف طولانیمدت (از دست رفتن درآمد، آسیب به اعتبار برند، جریمههای قانونی)، این سرمایهگذاری تقریباً همیشه مقرونبهصرفه خواهد بود.
- admin
- 5 دی 1403
- 259 بازدید







